



Although the genetic information is contained in the nucleotide sequence, the data stored in such way can only be interpreted in a spatiotemporally coordinated manner if sequence-specific protein factors bind to selected sites on the DNA strand. This recognition is governed by a code much more intricate than the genetic code itself – it depends on the sequence, steric and geometric constraints, post-translational modifications, the presence of other macromolecules and the competition between different kinds of interactions.
For this reason, the sequence specificity code is predominantly probabilistic and degenerate: identical DNA sequences can be bound by different proteins, and identical proteins can bind different sequences. In the cell nucleus, the dynamic search of a target sequence is a complex process. In eukaryotic cells, billions of binding sites exist that need to be interrogated, with little difference in affinity to tell a target site from a non-target one, so that a "naive" random approach to sequence search would be too time-consuming for the cell. However, proteins evolved to utilize the so-called facilitated diffusion mechanism, in which they combine two modes – the one-dimensional "sliding" along the DNA helix and the three-dimensional "hopping" between different, potentially distant, chromatine segments.
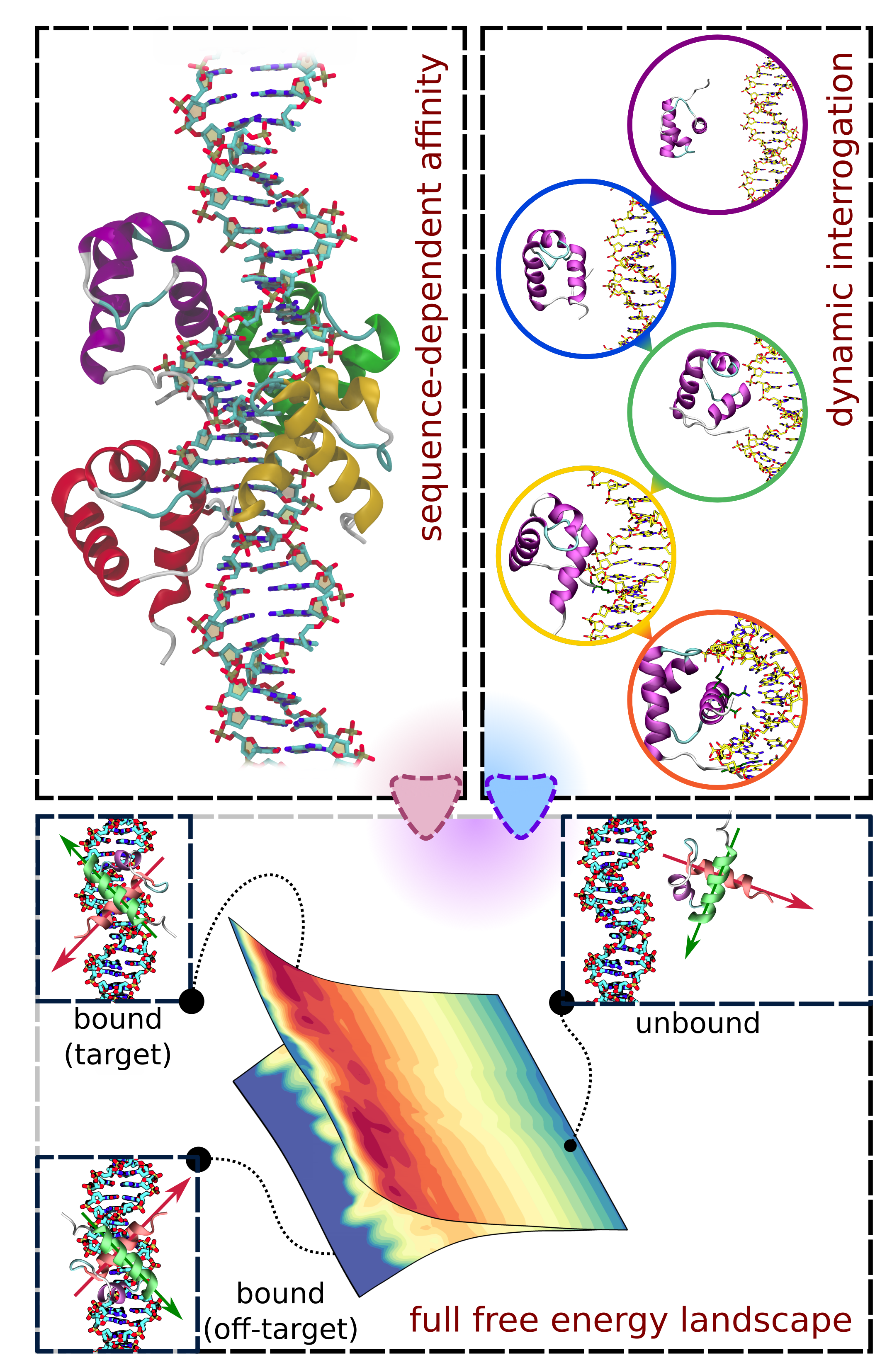
The subgroup of sequence-specific DNA-binding proteins studied in our lab are the telomeric proteins. Telomeres – nucleoprotein structures located on the ends of linear chromosomes – conceal the termini of chromatin to protect them from DNA repair mechanisms that would otherwise recognize them as dangerous DNA strand breaks. Telomeric proteins also help avoid gradual loss of genetic information during replication, as well as maintain the functionality of chromosomes e.g. during mitosis. These functions are performed by the shelterin complex, composed of six proteins – TRF1, TRF2, POT1, TPP1, TIN2 and RAP1 – two of which (TRF1, TRF2) directly bind double-stranded telomeric DNA, and another (POT1) binds single-stranded telomeric DNA located on the so-called 3'-overhang. Importantly, the mammalian telomeric sequence contains thousands of tandem repeats of the 5'-TTAGGG-3' hexanucleotide motif, so that the respective protein binding sites are immediately adjacent to each other. Such an arrangement – starkly different from the case of e.g. transcription factors, where individual binding sites are scattered throughout the genome – determines a different dynamics of bound telomeric proteins: while the high sequence-specific affinity ensures that they localize to telomeres, their interaction is much less static and allows for slow diffusion along the telomere, allowing for regulation of higher-order structures (D/T loops, G-quadruplexes, the shelterin).
Click to play: